Sample recordings based on selection weights from calc_selection_weights()
using spsurvey::grts().
Usage
sample_recordings(
meta_weights,
n,
os = NULL,
col_site_id = site_id,
col_sel_weights = psel_std,
seed = NULL,
...
)Arguments
- meta_weights
(Spatial) Data frame. Recording meta data selection weights. Output of
calc_selection_weights(). Must have at least the columns identified bycol_site_idandcol_sel_weights, as well as the probability of selection columns (those starting withpsel) anddoy.- n
Numeric, Data frame, Vector, or List. Number of base samples to choose. For stratification by site, a named vector/list of samples per site, or a data frame with columns
nfor samples,n_osfor oversamples and the column matching that identified bycol_site_id.- os
Numeric, Vector, or List. Over sample size (proportional) or named vector/list of number of samples per site Ignored if
nis a data frame.- col_site_id
Column. Unquoted column containing site strata IDs (defaults to
site_id).- col_sel_weights
Column. Unquoted name of column identifying selection weights (defaults to
psel_std)- seed
Numeric. Random seed to use for random sampling. Seed only applies to specific sampling events (does not change seed in the environment).
NULLdoes not set a seed.- ...
Extra named arguments passed on to
spsurvey::grts().
Value
A sampling run from grts. Note that the included dataset is spatial, but is a dummy spatial dataset created by using dates and times to create the spatial landscape.
Examples
s <- clean_site_index(example_sites_clean,
name_date_time = c("date_time_start", "date_time_end")
)
m <- clean_metadata(project_files = example_files) |>
add_sites(s) |>
calc_sun()
#> Extracting ARU info...
#> Extracting Dates and Times...
#> Joining by columns `date_time_start` and `date_time_end`
params <- sim_selection_weights()
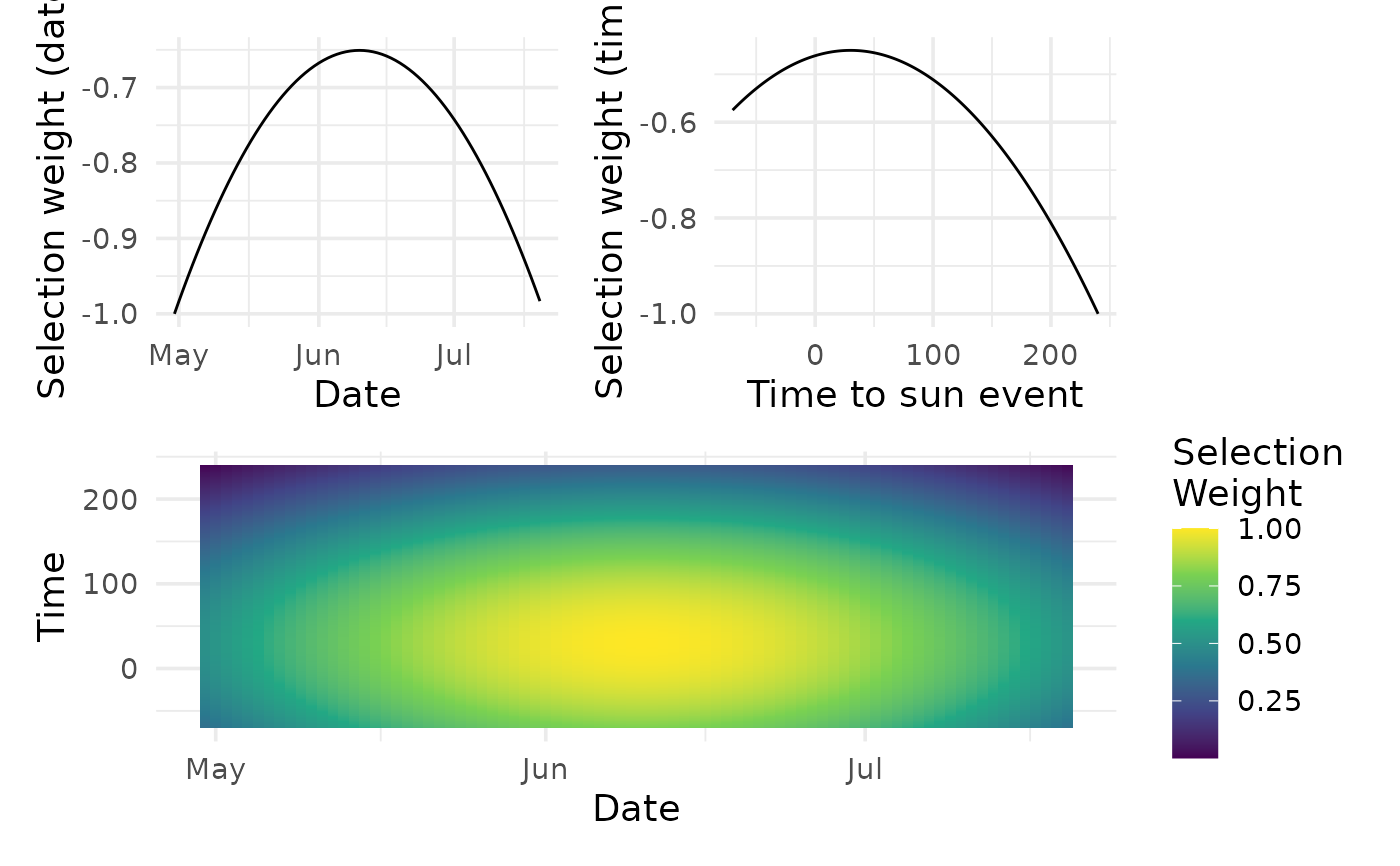 w <- calc_selection_weights(m, params = params)
# No stratification by site
samples <- sample_recordings(w, n = 10, os = 0.1, col_site_id = NULL)
# Stratification by site defined by...
# lists
samples <- sample_recordings(w, n = list(P01_1 = 2, P02_1 = 5, P03_1 = 2), os = 0.2)
# vectors
samples <- sample_recordings(w, n = c(P01_1 = 2, P02_1 = 5, P03_1 = 2), os = 0.2)
# data frame
samples <- sample_recordings(
w,
n = data.frame(
site_id = c("P01_1", "P02_1", "P03_1"),
n = c(2, 5, 2),
n_os = c(0, 0, 1)
)
)
w <- calc_selection_weights(m, params = params)
# No stratification by site
samples <- sample_recordings(w, n = 10, os = 0.1, col_site_id = NULL)
# Stratification by site defined by...
# lists
samples <- sample_recordings(w, n = list(P01_1 = 2, P02_1 = 5, P03_1 = 2), os = 0.2)
# vectors
samples <- sample_recordings(w, n = c(P01_1 = 2, P02_1 = 5, P03_1 = 2), os = 0.2)
# data frame
samples <- sample_recordings(
w,
n = data.frame(
site_id = c("P01_1", "P02_1", "P03_1"),
n = c(2, 5, 2),
n_os = c(0, 0, 1)
)
)